Introduction
I doubt that not many New Yorkers know that there are 22 lines (27 if including SIR line and express lines) are there in the New York subway system like almost no one knows how many veins do we have in our body. The over complex MTA subway system is like the veins of New York City, connected the five boroughs and vitalized the metropolitan area. People live and travel in the city relied on the subway system so much, which made it become one of the primary factors that influence real estate prices. The logic is clear: the easier the commute, the more expensive real estates. However, real estate prices also affected by many other factors like schools, hospitals, security, etc. Therefore, it would be interesting to ask that which is the “most expensive” subway line in the New York City.
Data Source and Prepar
In order to demonstrate the real estate sales price, I utilized the Department of Finance (DOF)’s NYC Citywide Annualized Calendar Sales Dataset (December 19, 2018 Version), retrieved from NYC OpenData, March 2018. Its covers all recorded property selling in the year 2017 and include factors of sales prices and dates, property addresses, geocodes, etc.
I also accessed each subway station’s geolocation from the Subway Stations dataset on NYC OpenData, provided by MTA, as well as the Health Area GeoJson file from NYC Planning data portal.
Data Cleaning and Preparing
These two datasets require limited efforts of cleaning, in the beginning. However, when I later dived into the spatial analysis, a serious problem occurred. All the subway stations are independent points and had no sequential data. Which means I won’t be able to create lines with these points in Carto. I also couldn’t find a satisfied dataset that meets my requirement, so I had to spend hours to manually add the sequential column. In case anyone meets a similar problem, I uploaded the optimized dataset to Kaggle, please feel free to take advantage of it.
Update: There is a better subway line data source in NYU Spatial Data Repository, if you are seeking for a shapefile instead of a NYC subway station data with sequential columns, it would be a better choice.
Inspiration
Although the approach was extremely struggling, my early idea was actually very simple. all I wanted was to create a choropleth map that shows the sales prices of real estates by neighborhood. That was so boring, although choropleth maps like this following map, which utilized 9 colors (WHAT?!), but still meaningful, and the trend was clearly showed with the smart color setting and legend design. However, this map includes two primary variables, and my property sales dataset won’t allow me to create something like this. That’s when I decide to include another dataset.

made by Nathaniel Alexander Douglass
I didn’t get a sophisticated idea until Prof.McSweeney introduced one of her projects to me in another course. The project, “Language above the Subway“, shows the usage of different languages in different subway lines and stations.


Although this is not a mapping project, it was based on spatial analytics. With adding an one mile buffer, the author selected the census language data, and defined the subway station’s language ratio.
Visualization Process and Thoughts

After upload all my data in Carto, I firstly created a simple but pretty dot density map that includes all the data points. (Layer Properties Sold in 2017)

Then I added the health area shapes, which is considered close to the neighborhood area to the map, and calculated each area’s average sales price. It is worth mentioning that Carto provides five different options here: sum, average, min, max, and count. Since the sales dataset does not include all properties but only the ones have been sold in the year 2017, the sum value won’t make a lot of sense. The count value would make sense but that would tell a different story. (Layer Property Sales Price by Neighborhood)

After creating the choropleth map, I added the Subway Stations on the map. In Prof.McSweeney’s language project, she added a 1-mile buffer for each subway station, in order to reflect the affected area of each subway station. However, 1 mile is considerably large in the New York City area, especially in Manhattan. Hence I decided to add 500-meters buffers for each of the stations, which is the usual distance people would walk to the subway station, and then calculated the average value of the sales prices in each buffer zone. Unfortunately, since there are way too many points on the map, the map is now too dense to be meaningful. (Layer Subway Station 500m Buffer)

As mentioned formerly, I later decided to add a sequential variable to my data, and with that, I successfully connected all the subway lines and created a five hundred meter buffer with it. Here I excluded all the branch lines such as A Line Ozone Park Branch, due to the limitation of Carto, and it won’t influence my result too much. However, the result is still not very satisfying, that all the buffers are clotted with each other and the colors can barely be identified. (Layer Subway Line 500m Buffer)

Therefore, I decided to add another subway line layer that has thinner lines as the color code container. In order to indicate the buffer zone, I left the buffer layer with only boundaries. Although it’s still a little messy, it is much better than before. It is also worth mentioning that in addition to the default style setting, I manipulated the line endings and joints with simple Carto CSS lines (line-cap: round; and line-join: round;), which made these lines corresponds to the buffer much better. (Layer Subway Line Sale Prices Color Code)
(Layer Subway Line Sale Prices Color Code)

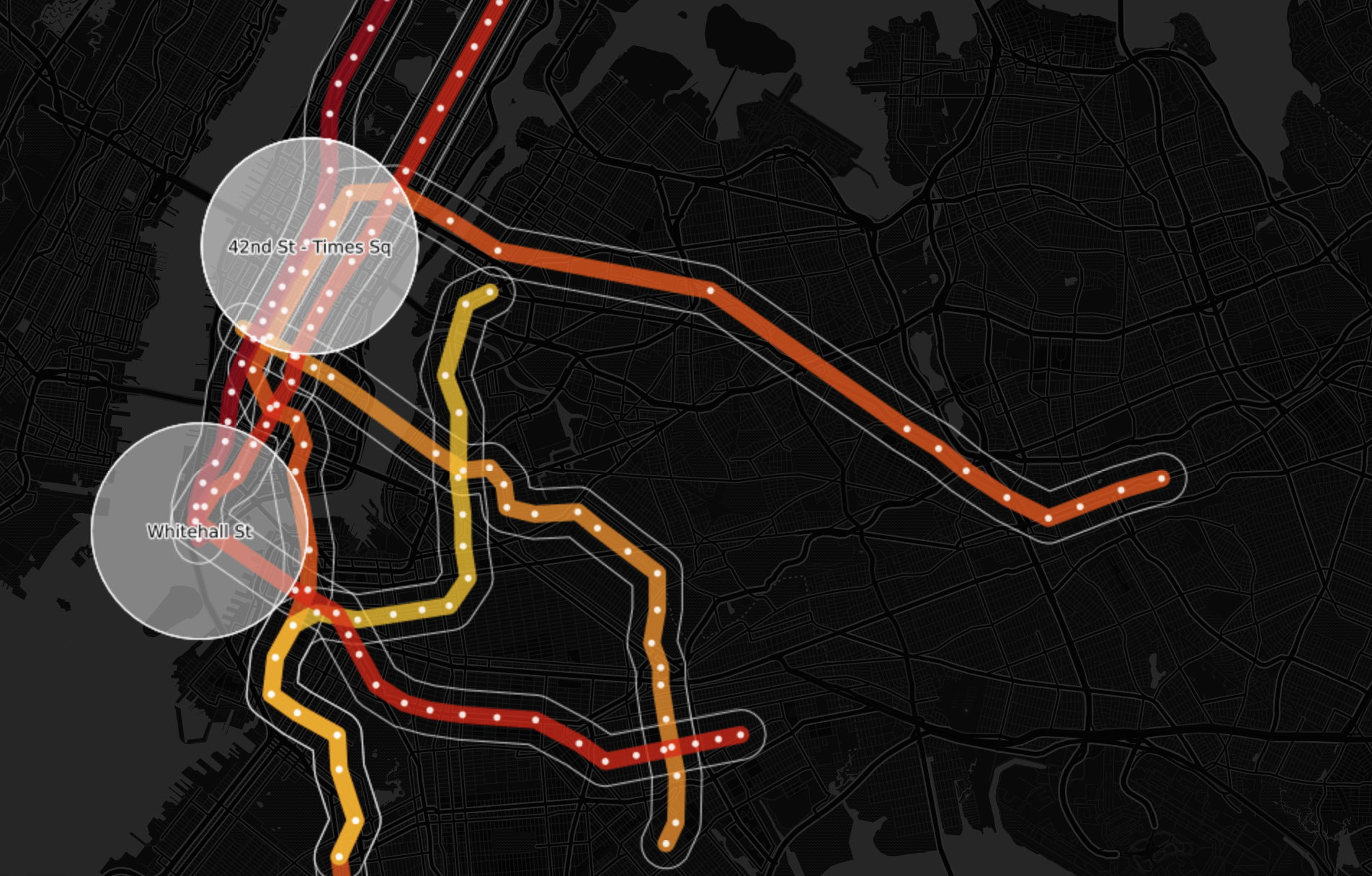
In order to make the map more informative, I added an additional layer to indicate each station along the subway lines, which also made it similar to the actual subway map. For the same reason, I added pop-up windows for both subway lines and stations. In the interest of user experience, both pop-up windows can either be activated by hover (desktop) or click (mobile). (Layer Subway Stations)

Lastly, with the function Link the Second Layer, I connected the “Subway Line 500m Buffer” and “Subway Line Sale Prices Color Code” layers to the “Subway Stations” layer, and created a widget based on subway lines, which allows user to turn on and off subway lines, and show each of them as a small multiple, eventually solved the over dense problem.
Result and Observation


With the value filter widget, it is easy to find out that the “most expensive” subway line is Line 1, with the average price at 2.8 million dollars, and Line 7 was the least expensive line, with the properties along it averagely sells only 0.9 million dollars.

I then started wondering which are the “most expensive” stations, In order to figure it out, I added an extra buffer layer based on station. With a filter greater than 10 million dolors, there were still around ten stations left. Since they were mostly clotted together, I hand-selected two representative ones – as being shown above, the average property price in the Time Square station is over 20 million dolors.


Lastly, I used the formula widget to calculate the original sales data found out New York City’s overall average property sales price. This widget can also show the average sales price of the whole of the New York City area. What’s more, it would be meaningful to include another widget that shows the average price of only the subway line affected area as a comparison, which requires an additional layer that dissolves instead of intersects each buffer. With these two widgets, we can see that the property price is 0.4 million dollars higher than the overall average price of the city.
Reflection
There are several things that I want to change if I got a chance to revisit this project. The first thing I’d like to address is about the dataset. I have to admit that I have made some serious bad-decisions while I was cleaning the data. I didn’t realize them until I tried to make some further analysis with the stations instead of the lines.
The consequence of the first bad decision confused me that whenever I tried to link two layers with subway station names, Carto would automatically add hundreds of new rows into the dataset. Now I understand that there are duplicate subway station names! When I was cleaning the subway station data, I split the stations that have multiple lines crossing (transitions), so each row will include only one station on one line. It is actually better when I just need to analyze things about the subway lines. However, when I was trying to analyze the stations, the “name” column stops being a unique key, and that explains why Carto would add rows into my data.
Another bad decision was that when I was adding the “stops” as a sequential factor, I also manipulated the “name” data. As people know, the names of NYC subways stations are usually street names, with or without a crossing road’s name, or a landmark place such as Times Square. These added features are not usually added in front of the street name. In order to get a more reasonable dataset, which I can split easily after. However, when I was doing it, I forgot to make a back up of the original name column, which is the name being shown on most of the subway maps. I also didn’t treat the names with additional crossing streets and the names with landmarks differently, which might require extra steps to distinguish.
If I got a chance to revisit this dataset, the first thing I would do is to add a prefix to the stops with subway line names, eg. change 19 to C-19. And I would add three additional columns, “street”, “crossing street” and “landmark” and keep the original station name column.
Furthermore, there are several glitches of the map. One is that the map is now showing the average sales prices as float numbers, which is not friendly to users. Instead of a tens of digit number, it would be meaningful to show an approximate value like 1.5M. What’s more, the current map answers the question of which is the most expensive subway line, but as an interactive map, it should also allow users to view results of stations.
I was also a pity that I missed the chance to make an animated map, as well as the chance to explore Carto CSS and SQL features. Compare with QGIS and ArcGIS, Carto is a more intuitive and quicker tool to make a map and analyze spatial data. Although I might stick with QGIS, it would be nice if I can find another chance to try these features out.
