Introduction
Network Data Analysis, as one underestimated tool of data analytics, with its visualization’s complex appearance, always triggered my curiosity. As part of my experience in Prof.Dr.Sula‘s Information Visualization class, I played a little bit with Gephi, intended to understand Gephi’s layout algorithms as well as the actual meaning clustering process with practice.
In this practice, I created a network among the registered players in FIFA 2019, a well-known video game of soccer, with the nodes as players, and the edges as the shared skillset. In this network, the players have more similar skill set will have a stronger connection.
Examples and Inspiration
Before I got my hands onto Network Analysis, it seems so complicated and mysterious. The nodes and edges were presenting themselves as stars and orbits on the background of the universe. Before I started working on this project, I watched several videos and tutorials, in order to know more about clustering. One really helpful video tutorial is Using Gephi to visualize and understand communities, which clearly explained the clustering process and taught me some strategies of clustering.

On the other hand, since I am going to deal with a considerably complex network, I found another example of a social network. The British researcher Andy Patel‘s article Why Social Network Analysis Is Important introduced the strength of network analysis, and provide a sophisticated example of network visualization. Although all the projects he has done are accomplished by Python, the design decisions are still worth noticing. One example provided in this article shows the Twitter network about “Brexit (British quit EU)”. Each node represents a user and their connections are actions like mention, retweet, or reply. One feature I really took from this example is the consistency of color (not in early stages). Each image of this project is showing how the network is like in different time frames, and the consistent coloring really helped the audience understand the transformation.


Data Source
In order to know the whole procedure of network analysis, I decided to generate my own network data table. I firstly adopted FIFA 2019 Complete Player Dataset from Kaggle.com, which includes detailed attributes of each registered player in FIFA 2019 database. These features include the basic information of these players like Club, Nationality, Age, Height, Weight, Position, etc, and their 33 different quantified skill attributes such as Crossing, Short Passing, Dribbling, etc. Each of these features is rated by a 100 score (higher the better). Considering that I will need to color code these players as groups, and Club or Nationality will be overabundant as grouping features, I also found Country and Continent Codes List at DataHub, and scraped FIFA 2019 Clubs and Leagues from EA.com, which provides the classification of countries and clubs.
Data Cleaning and Preparing
– Prepare the Network Matrix
Before I created the network table, the first thing I really had to do was to define the connections of each player. There were two potential connections that could be used. Besides the quantified skill scores, there is another quantified attribute that defines each player’s performance at different positions on the field. Considering that creating a network based on skills and see whether the clustering would match the players’ dominant position would be interesting, I decided to utilize the skill data as the connection feature.
Unlike the classic article-keywords example, the connection in this dataset is subtle. Unlike keyword, all players in this dataset are scored in every skill. Therefore, what I needed to do was to make the table binary. Based on my experience of playing FIFA 2019, I defined that players will be “good at” one skill only when they have a score in this skill higher than 80. To accomplish this, I used R. For instance, I used the following code to subset only the Crossing scores that are higher than 80 and created a matrix with only players who are good at Crossing. I replicated this process for the other selected skill attributes.
> Crossing <- fifa2019[c(“ID”, “Crossing”)] #1
> Crossing <- Crossing[which(Crossing$Crossing >= 80),]
There are 12 skill attributes were selected to generate my final network table, for that these selected skills reflect positions of players the most (see the Reflection section for more information). Then I merged all the matrixes to one table with the following code and put the number 0 into the blank cells (whereas the skill the player is NOT good at). After backup the dataset, I set all the values greater than 80 (the “good at” values) to 1.
> PlayerSkill <- Reduce(function(x, y) merge(x, y, by=”ID”, all=TRUE), list(Crossing, ShortPassing, LongPassing, Dribbling, BallControl, ShotPower, Marking, StandingTackle, SlidingTackle, GKDiving, GKReflexes, GKPositioning))
> PlayerSkill[is.na(PlayerSkill)] <- 0> SkillList <- PlayerSkill # backup the dataset
> SkillList[-1][SkillList[-1] >= 80] <- 1
After running this, a binary matrix was generated, which shows what each player is good at. Note that in order to avoid duplicated Names, I used ID as the primary key instead.

I then expanded each of these skills using the expand.grid function. Taking Crossing again as the example.
> CrossingYes <- SkillList[which(SkillList$Crossing == 1),] #1
> CrossingEdges <- expand.grid(CrossingYes[,”ID”], CrossingYes[,”ID”])
The will give me lists of players who shared the same attribute. I then used the rbind function to create a network table.
> fifaEdgelist <- rbind(CrossingEdges, ShortPassingEdges, LongPassingEdges, DribblingEdges, BallControlEdges, ShotPowerEdges, MarkingEdges, StandingTackleEdges, SlidingTackleEdges, GKDivingEdges, GKReflexesEdges, GKPositioningEdges) # row-bind all the datasets as lists
> fifaEdgelist <- subset(fifaEdgelist, Var1!=Var2) # omit duplicates
> fifaEdgelist[“count”] <- 1 # at the weighted container> fifaWeighted <- aggregate(fifaEdgelist$count, by=list(source=fifaEdgelist$Var1, target=fifaEdgelist$Var2), FUN = sum) # count the weight
After omitted the self connecting edges, I aggregated the weight value, and the network table should be prepared by now. However, this table now contains more than 15 million edges which are totally beyond the amount Gephi’s capability. Therefore, I filtered out the edges weighted smaller than 3 ( < 3), and gain a network with around 20 thousand edges, which is a more meaningful size for a Gephi visualization.
– Prepare the Node Table
In addition to the network table, I made a note sheet (AKA the node table) to demonstrate extra details of each node. The original FIFA dataset already provides a variety of details, so the first thing I did was simply subset the data and create a table of selected columns from the original dataset.
> noteTable <- fifa[c(2, 3, 4, 6, 10, 12, 22, 27, 28)] # columns
># 2-ID, 3-Name, 4-Age, 6-Nationality, 10-Club, 12-Value, 22-Position, 27-Height, 28-Weight
These columns include the information that I considered having a potential of categorizing the players, such as Values (the price of each player in the transfer market), Clubs, Nationalities, and so on. These variables are quite useful, but since this dataset covers tens of thousands of players, each of these parameters that I chose to categorize them won’t really do their job – there are too many categories. Therefore, I need to “group the groups” first. One obvious approach is to group countries by continents. Here’s when the Country and Continent Codes List kicks in. Since the country names in this list have suffixes (eg. China, People’s Republic of) when the Nationality in the FIFA dataset has only the plain country name (eg. China), I need to remove all the suffixes in the country-continent table, in order to match these two datasets.
> note$CountryName <- note$Nationality
> country$CountryName <- country$Country_Name
# it would be better to backup the original columns as references> country <- separate(country, “CountryName”, paste(“CountryName”), sep=”,”, extra=”drop”)
> note1 <- merge(note, country, by.x = “CountryName”, by.y = “CountryName”, all.x = TRUE, incomparables = NA)
These two lines worked for most of the countries. However, there were some tricky countries won’t fit. In order to check whether all the countries were matched, I utilized the unique functions. Since the countries which didn’t match with the continent table won’t have a value in the Continent_Name column, I select all the rows that has their Continent_Name valued NA, and check what countries are they.
> check1 <- note1[is.na(note1$Continent_Name),] # select only rows with Continent_Name == NA
> unique(check1$Nationality) # get unique values
> # check ends
There weren’t too many of them. So I manually replaced each of these countries BEFORE the checking codes, until all countries are categorized by continents.

There were few outliers in this process, including the islands of UK, which are not “nations” but attending FIFA individually, and Kosovo, which is a region of Serbia (a Europe country) newly claimed independence and is not commonly admitted. Luckily they are all in Europe, so I simply replaced the remaining NA values in the Continent_Name column with Europe.
Another obvious approach is to group clubs by the Leagues they belong to. My attempt was using the data I scraped from FIFA 2019 Clubs and Leagues. However, since the club names have much more variations and will take too much time to match, I gave it up for this project.

Another important grouping is to group the player positions. I tried two different approaches here. The first is simply group them by the fields they would be on. All eleven players in soccer can easily be categorized by Defenders, Midfielders, Forwards, and GoalKeeper.
However, in the real world practice, soccer players’ position is much more complicated. In FIFA 2019, these four simple categories are subdivided into 27 positions.
> unique(note1$Position)
[1] “LB” “CAM” “CM” “LM” “CDM” “RB” “LDM” “LCM” “CB” “GK” “RW” “RM”
[13] “RCB” “RS” “RCM” “ST” “LW” NA “LCB” “RDM” “RWB” “LF” “LS” “RF”
[25] “LWB” “CF” “LAM” “RAM”

After reading some articles that explain each position code’s meaning, I added a new column to the dataset and entered values based on their positions. I named them “ATT”, “MID”, “DEF” and “GK” referring to the four main groups.
> note3$Field[note3$Position == “LW” |
note3$Position == “RW” |
note3$Position == “RS” |
note3$Position == “LS” |
note3$Position == “ST” |
note3$Position == “LF” |
note3$Position == “RF” |
note3$Position == “CF”
] <- “ATT”
On the other hand, as most soccer fans would know, this simple grouping won’t reflect each player’s actual function. One standing out example is the side back-field players (LB and RB). They are usually fast runners and will dive deep to the enemies’ half and attending attack. Therefore I decided to add another column and categorize the players by their actual function. The code is similar, but the decision was much harder. It is because this decision includes a lot of subjective “human” decisions. Eventually, I categorize them into seven groups including Goal Keeper, Back, Wing, Defence, Center, Attack, Strike. It was based on my own understanding of soccer and experience in playing FIFA 2019.
Since the decisions were so subtle and subjective (so “human”), I had no strong confidence in this categorization method. Compare to how I categorized these features, the primary goal of this project reappeared: how would the network analysis algorithms do differently?
Visualization Process and Thoughts
To answer this question, I imported the note table (which were further refined in OpenRefine, changed numeric values, such as Values and Height, to numbers and removed the R generated row number column) and network matrix into Gephi and filtered out the no-connection nodes (which were imported with the note table).
– ForceAtlas2 Algorithm

My first attempt was to use the ForceAltlas2 algorithm (use the same equation with the ForceAtlas but optimized) to calculate how the network looks like. For the parameters, I checked “Dissuade Hubs” which “Distributes attraction along outbound edges […and] hubs attract less and thus are pushed to the borders”, and makes the graph’s boundary more integrated. (MATHIEU JACOMY, 2011) I also checked the “Prevent Overlap” option to avoid overlapped nodes and set a relatively high “Gravity” to pull the GK cluster closer to the main lump.
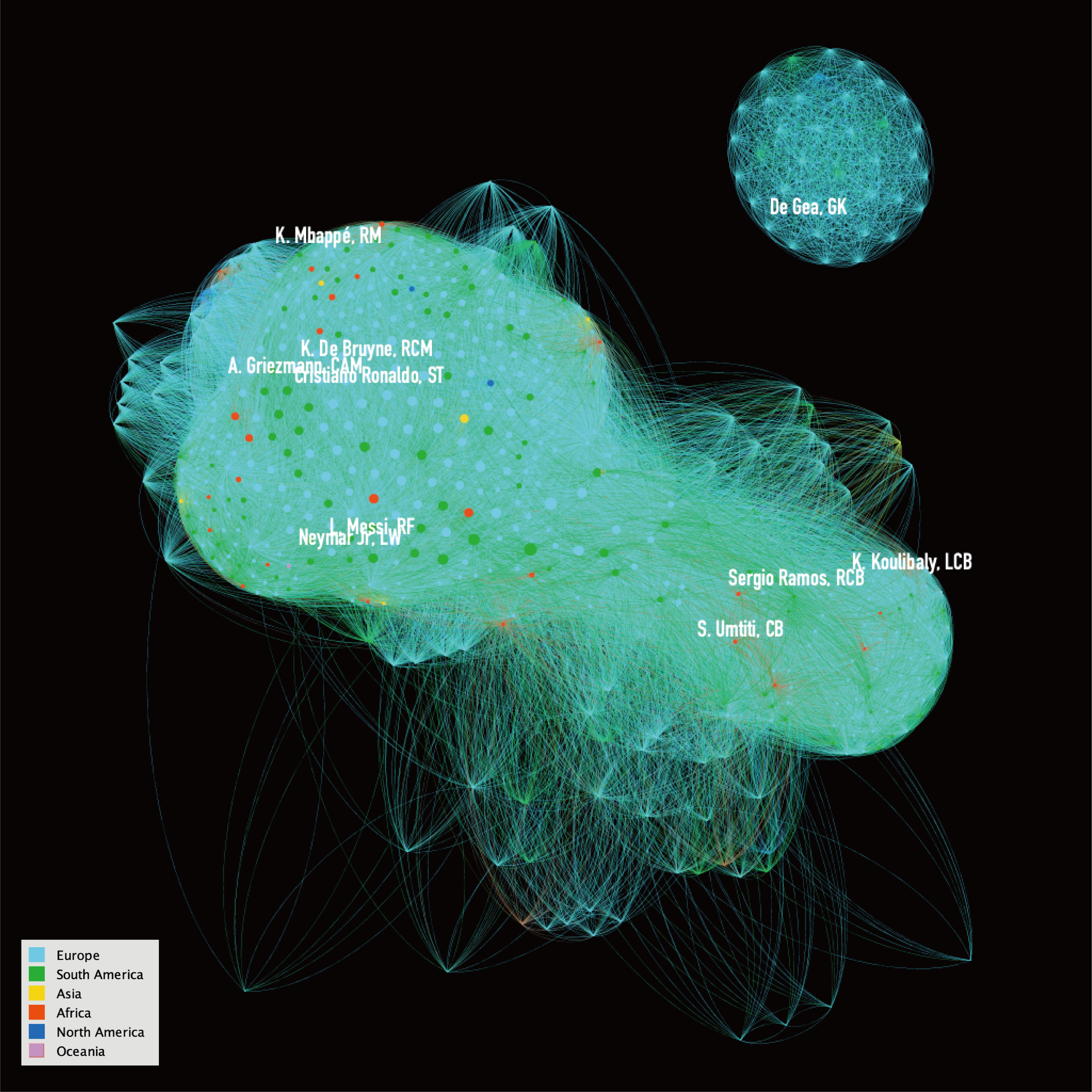
In order to check whether the result would fit my “human” grouping, I colored it by three different partitions. One is modularity class (calculated by Gephi statistic, resolution = 0.85), another two are the “function” and “function” groups, which were grouped by my subjective consideration or real-world classification. For the labeling, I decided that to label only selected players, instead of creating a text lump with no legibility. The selecting of players is based on their value on the transfer market. I labeled the top two most expensive players of each “Field” group. I later switched to the most expensive player in each modularity class plus the three most famous players (C.Ronald, L.Messi, and Neymar Jr), for the reason that it will be more helpful with analyzing the cluster groups.

Left to right: 1. “Human Defined” Function, 2. “Real-world Grouped” Field, 3. Gephi Clustered Modularity Classes
Click to view full-size image
Although it is clear that the human defined groups are considerably “messier” in the layout, we can still see that the cluster in the right bottom corner is similar among all three graphs, and all the GKs are floating outside of the main network since they have no shared attributes with other players. On the contrary, the most midfielders and forward players are merging together and mixed with a small number of backfield players, while the modularity class has only one group are not really clustered.
– Yifan Hu Proportion Algorithm
After I obtained these graphs, I tried another force-directed algorithm, Yifan Hu Proportion Algorithm. And I decided to abandon the “Function” grouping because of that its nodes are too discrete, and hard to analyze. In the Yifan Hu layout with Field coloring (figure below, left), it is easier to see that the forward players (orange dots) tend to cluster in the right up corner, while larger nodes (with higher degrees) appears in the center, mixing with midfielders. It is also noticeable that the largest blue dots (defenders) present in the central area. If we compare the Field coloring graph with the cluster coloring graph (figure below, right), it is not hard to tell the yellow, red, and orange communities in the graph are subdivisions of the mix of midfielders and forward players. The cyan nodes are interesting since they congregate together while some outliers are totally off-grid and appeared in the center.
Left to right: 1. “Real-world Grouped” Field, 2. Gephi Clustered Modularity Classes
Click to view full-size image
Base on these attempts, I got a sense that the modularity class somewhat reflects the real-world grouping and human’s expectation, but there are obvious differences. Understand and analyze these differences might help researchers obtain a deeper understanding of some hidden relationships within the nodes in the network. In this project, the relation would be the similarity among soccer players skilled in different positions. The observation of this might help FIFA 2019 player or even actual soccer teams making decisions such as whether a defender can alternate a striker when no other substitute player is available.
On the other hand, when I was coloring the network with Continents, players from different continents distributed sparsely, which indicates no clear patterns. The only observation is that most top players are from Europe and South America.
Colored by Continent Group
Click to view full-size image
Similarly, when the graph is colored by ranges such as player’s Height, Weight, or Value, the graph is less meaningful. Even though, these graphs still tell facts like backfield players and goalkeepers are usually higher and heavier than front field players and midfielders. Assumeably, the back positions requires more physical strength. For the value graph, we can see the red dots are mostly showing in the center of the midfielder/front-field-player group, which might demonstrate that the backfield players are considerably cheaper in the transfer market. However, these kinds of facts can be better shown in bar charts or scatter plots.
Left to right: 1. Value Range, 2. Heights Range, 3. Weight Range
Click to view full-size image
After trying all these groupings, I decided to focus on the modularity class group and understanding the actual meaning of each group in this method. In the interest of knowing the difference between algorithms, I utilized the Fruchterman Reingold Algorithm for the final graph. After rendering the rough graph, I used the Rotate, Expansion/Contraction, NoOverlap, and Label Adjust algorithms to adjust the graph and gain the layout below. I was satisfied with it and started to analyze the actual meaning of each modularity community.
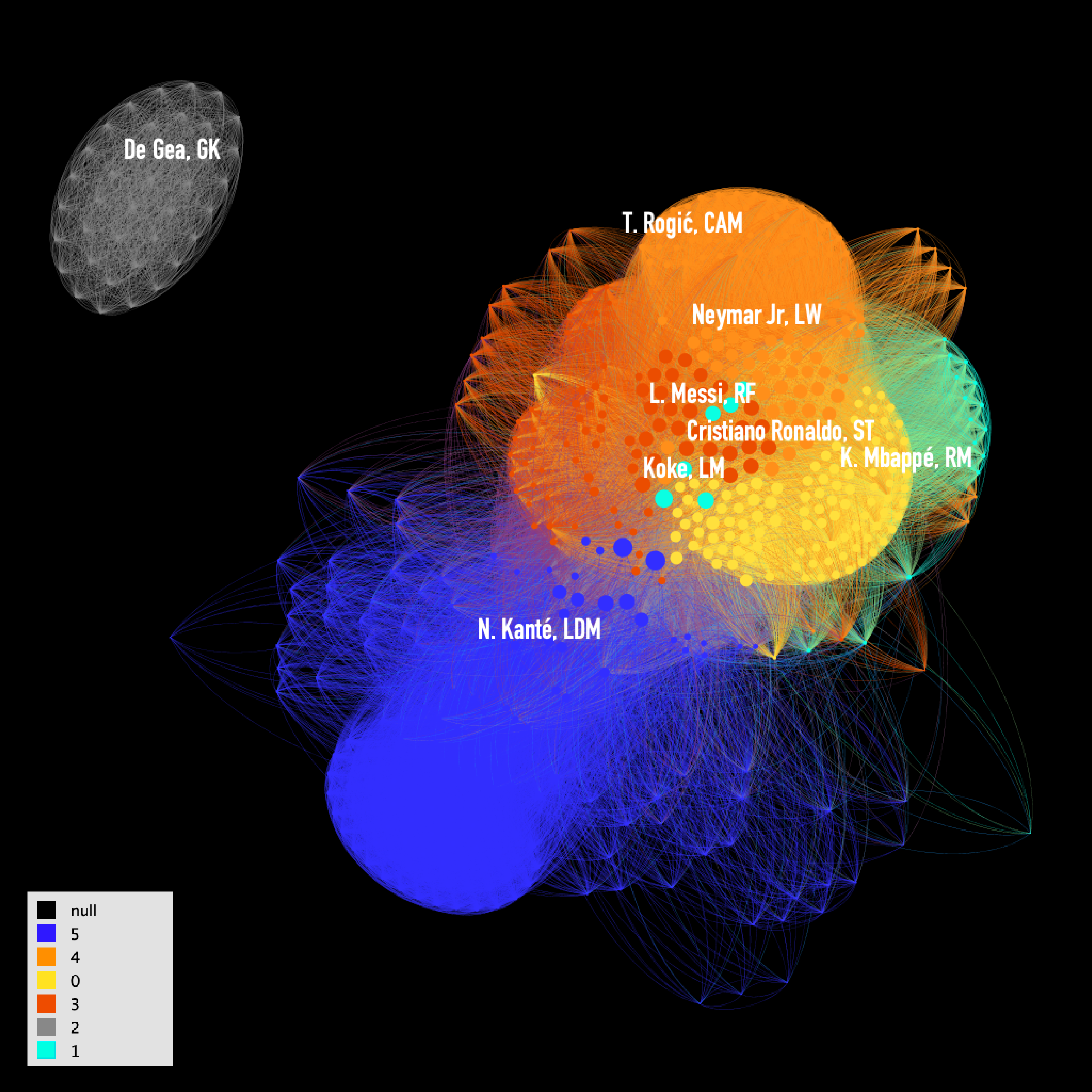
Colored by Gephi Clustered Modularity Classes
Click to view full-size image
Result and Observation
With the resolution of 0.85, the modularity class method returns six communities plus null. To understand what does each cluster mean, I filtered each cluster out and labeled them with each player’s main position. The blue and grey cluster are the easiest to tell. The grey one is obviously a separate group of Goalkeepers. The blue one includes backfield players and some “DM” players, which are midfielders but their job is to help to defense in the soccer games, which makes perfect sense they somehow share some attribute with back filed players and have a closer relationship.

On the contrary, the other four components are relatively complicated. It is not hard to tell that all these four clusters are mixes of mostly Midfielders and Forward Players. It is noticeable that the orange cluster has a large portion of Strikers (ST, LS, RS) and Forward Players (CF, LF, RF), and front Wingers (LW, RW), and there are no Defending Midfielders are in this chunk. Therefore, we can assume that this cluster is the “Attackers”. The cyan one, although it is relatively smaller and sparse, can be classified as the “Wingers” cluster. It is because except for three CM/CAM (center midfielder) players, the rest are all side field (L/R) players. It is worth mentioning that there is a considerable amount of backfield players (LB/RB/LWB/RWB) in this group, which is totally reasonable because in soccer games it is a common strategy the backfield wingers dive down to the enemy field and assist the attack.

The red cluster is trickier. It includes players on a variety of different positions. However, when I labeled it with Field, the fact that this is a group of midfielders with a tendency of attacking became clear.

The yellow cluster is the most complex one. Although calculate this cluster separately with ForceAtlas2 helped present a better trend, the actual meaning of this cluster is still mysterious. The blue and red sub-groups show a tendency of defense (with a lot of Defend Midfielders), while the yellow cluster contains many Foward Players.

It left me no choice but dig into the raw data of this group. After I sorted the table with value, I found that this group contains almost half of the most expensive players, including Lionel Messi. (Another group with a large portion of top players is the orange one, Cristiano Ronaldo is in that group.) What’s more, these players are usually the most considered comprehensive players, attack (L.Messi) or defense (Pogba). Therefore, this cluster might include the most comprehensive players, which is usually a valuable characteristic for midfielders. This explains the mix.


Finally, after playing with this network, I exported it to an SVG file and changed the edges’ opacity and added a legend in Illustrator. I inherited my labeling strategy and labeled only the most valuable player in each cluster. I also labeled the big three (Messi, C.Ronald, and Neymar), since they might be the players for which most audience would first search. Also, in the final graph, it is not hard to see that the most valuable players (MVP) are in the center of the network, for the reason that they tend to have a higher score in most attributes and this network considers sharing high score attribute as connections, which gave the MVPs more centricities.

Reflection
There was so much fun in my first attempt of network analysis. From this project, I gained a better understanding of network analysis, that a network graph is more than a “pretty image” but also a powerful analytic tool. In this project, I utilized the FIFA 2019 dataset to understand the difference between human grouping and algorithmic clustering. For now, I would argue these two methods are supplements to each other. The latter provides a deeper understanding of data while the former one helps people understand each cluster’s actual meaning.
On the other hand, there is one other approach. When I was creating the Network Matrix, I didn’t select all the players’ technique attributes. Instead, I made a “human decision” and chose only 12 out of 33 attributes.
> #Crossing, ShortPassing, LongPassing, Dribbling, BallControl, ShotPower, Marking, StandingTackle, SlidingTackle, GKDiving, GKReflexes, GKPositioning
This decision is based on my understanding of soccer. For instance, Marking, StandingTackle and SlidingTackle are main skills of defenders, while ShotPower, Crossing, BallControl are skills of strikers. In my early consideration, using these attributes will help to create a stronger connection among similar players. However, now I think this decision might cause the “mix” of Midfielders.
Although I can include all the features and create a heavier network, one alternative approach is to utilize a method called Principal Component Analysis. I found this article by Kan Nishida later when I almost finished this project. Coincidently, Nishida is analyzing FIFA 2018 dataset.

As shown in the image above, the measuring line of all the GK skills is almost pointing in the same direction. Same things happened to the two Tacklings, Marking and Interception. The algorithm behind this is more complicated, but it basically means these variables are positively correlated. Therefore, if I chose only one variable from these correlated attributes, it might not influence the network pattern. It would be a nice experiment to do in the future, to see the difference of networks between two attribute selection strategies.
